
Jupinder Parmar
Deep Learning Applied Scientist, NVIDIA
jparmar2066 [AT] gmail.com
Group Robustness
Improving Model Performance on Atypical Subgroups of Data
 Overview:
Overview:
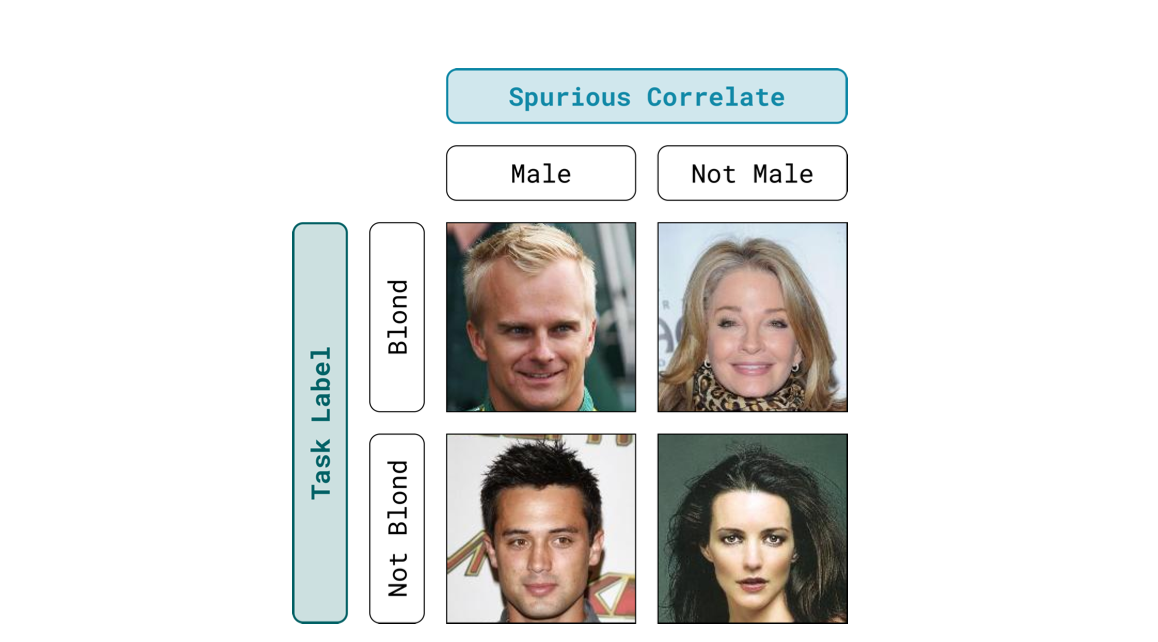
Standard machine learning models are typically trained with empirical risk minimization (ERM), which minimizes the average training-loss to produce models that generalize well to unseen test sets. However, even though state-of-the-art models are highly accurate on average, they can incur high error on certain groups of rare and atypical examples. Failures on these groups usually occur when models rely on spurious correlations: random associations that hold on average in the training set, but not on all examples from the true data distribution. For example, models trained to classify the presence of pneumothorax (a collapsed lung) from chest X-rays were observed to correlate pneumothorax with the presence of chest drains (a device used for the treatment of the condition). As a result, models trained via ERM end up falsely misclassifying positive examples without chest drains as negative. Spurious correlations exist in other applications such as facial recognition and natural language inference.
To avoid models that learn spurious correlates, we consider a set of pre-defined groups (e.g pneu- mothorax × chest drain) and train models that have low worst-group loss. Previous approaches have used group annotations to minimize the worst-group error during training time and have been able to improve worst-group accuracy without significantly hurting average accuracy; however obtaining group annotations for a large training set is highly undesirable as (1) it requires extensive labeling of all potentially correlated features and (2) the knowledge of a given spurious correlate can arise after training which may require relabeling.
Like previous works such as Just Train Twice (JTT) and GEORGE, we consider the setting where we do not have group annotations during training time and instead require them solely for a much smaller validation set for hyperparameter tuning and checkpoint selection. We propose a multi-task learning (MTL) framework to improve worst-group accuracy by training on multiple related tasks together. Intuitively, learning a joint representation across multiple tasks discourages the model from relying on the spurious correlates of any one task, as learning spurious features would degrade the performance on the other tasks. Furthermore, shared representations that are passed into individual task heads has a regularization effect that result in more robust and less overfit models, which should incur lower worst-group error. We propose an MTL framework for both ERM and JTT and show that MTL improves worst-group accuracy regardless of optimization procedure, while maintaining better average accuracy than JTT or similar approaches.